
DeepSeek: Driving the Next Evolution in AI

Although news about DeepSeek had been circulating since the release of its open-source V2 model, it wasn’t until January this year that DeepSeek truly made waves across the U.S. tech sector with the launch of its open-source R1 model. This model has outperformed OpenAI’s current o1 model in several public benchmarks. While the SOTA AI model is still OpenAI’s o3, We agreed with the statement that “DeepSeek's advances are more evolutionary than revolutionary.”
What sets the model apart is that: 1) it is open source; 2) The significant cost reduction in training—DeepSeek claims it trained the model for only $6 million, a contrast to OpenAI’s estimated ~$100 million cost for GPT-4.
Here’s a brief discussion of its technical breakthroughs and implications on the global AI industry.
Technical Breakthroughs
1. Architectural Innovations in V3:
While R1 brought DeepSeek in front of beyond the technical world, causing a 17% drop in NVDIA’s stock price, V3 has already proved its capabilities through two of its innovative architectural design methods:
MoE (Mixture of Experts)
Selective Activation: activates only 37 billion out of 671 billion parameters per token, using an auxiliary-loss-free load balancing system with dynamic bias adjustments
Pipeline Parallelism: DualPipe nearly eliminates communication overhead in distributed MoE models by overlapping computation and communication
Hardware Optimization: custom PTX instructions on NVIDIA GPUs, a rare low-level optimization approach in AI
MLA (Multi-Head Latent Attention)
Memory Efficiency: reduces memory requirements for storing conversation context, making inference more cost-effective and enabling longer conversations
Hardware Adaptation: further optimized it for H20 GPUs, improved memory bandwidth and capacity utilization compared to H100s
Low Cost: Multi-Token Prediction (MTP) system (predict multiple tokens simultaneously) + FP8 mixed precision training
On the solid base model of V3, DeepSeek developed R1-Zero.
2. DeepSeek-R1-Zero:
R1-Zero demonstrates that by using a simple RL setup:
a fixed training template (a reasoning process + the final answer)
+ a straightforward rule-based reward system (accuracy rewards + format rewards; w/o PRM)
+ the GRPO strategy (instead of PPO to reduce training costs of RL),

the model can autonomously learn to extend its reasoning time to solve complex tasks more accurately. This approach opens up a low-cost pathway for rapidly enhancing a strong base model’s capabilities without the need for extensive SFT data which requires a lot of human intervention.
Yet R1-Zero suffers from issues like poor readability and language mixing; to further improve the model, DeepSeek built R1.
3. DeepSeek-R1:
To solve R1-Zero’s limitations:
1. SFT using cold-start data from R1-Zero
2. RL with accuracy + format + consistency rewards
3. higher quality CoT data from above training + knowledge data from enhanced V3-base
4. RL with rule-based verification and human preference

Obtaining R1, its performance—only slightly behind OpenAI o1 0912 on GPQA while surpassing all o-series models in every other metric and excelling on CodeForces—powerfully demonstrates how the combination of SFT and RL can elevate a model to unprecedented heights.
Not only is DeepSeep’s ability to build high-performance large models impressive, but their technique of distilling a large model into smaller, more accessible versions is also remarkable.
Distillation:
Key learning: you can use high-quality reasoning data to elevate other models' performance without the need for additional RL at a fraction of the cost and effort of full-scale RL training.
DeepSeek generated superior CoT data from intermediate checkpoints from R1-Zero to R1 and combined it with V3’s knowledge data. Instead of fine-tuning their own V3 further, they used this rich data to fine-tune other models, such as Qwen and even Llama, and achieved robust results.
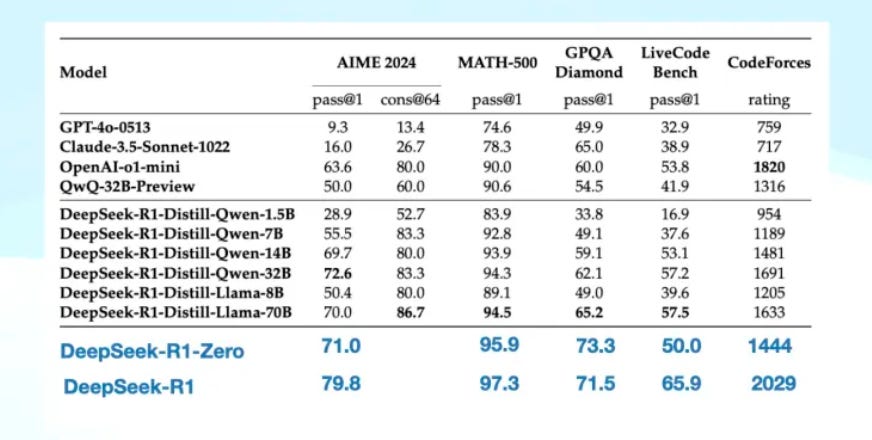
This approach demonstrates that, compared to traditional pre-training methods, using such data for SFT is very cost-effective because you don’t have to perform additional RL.
Impact on the Research Community
When V3 was released, it already gained recognition from leading academic circles in the U.S..

With the release of the R1 model, many have praised its open-source approach and the impact it has had on the entire research community, demonstrating that the same results can be reproduced locally at a much lower cost.

Being open-source means that researchers around the world can easily inspect, replicate, and build upon its work. DeepSeek's models now also serve as a new benchmark for evaluating the performance of other AI systems, pushing the industry to focus on achieving high performance while minimizing resource usage. It encourages researchers to explore new methods for optimizing AI models, such as model distillation and hardware-aware architecture design.
For decades, it was assumed that major IT breakthroughs came exclusively from the U.S., with other countries merely reverse-engineering innovations. DeepSeek shattered that stereotype by becoming the first Chinese startup in nearly 20 years to deliver a revolutionary solution. In this early AI era, it has sparked a new development roadmap—one that doesn’t depend solely on ramping up computational power—reshaping the competitive landscape between U.S. and Chinese AI enterprises and potentially narrowing the gap despite current compute restrictions.
Ultimately, from the perspective of human technological progress, competition and collaboration go hand in hand, and DeepSeek’s emergence is a signal for researchers worldwide to collectively push the limits of technology in the pursuit of AGI, regardless of their origin.
Implications for the Startup Ecosystem
Both training and inference are crucial for large models. Training sets the performance ceiling, while inference determines real-world usability—the speed and accuracy of which directly influence user experience. Optimizing inference reduces resource demands and operational costs, enabling broader deployment across diverse devices and applications. DeepSeek has shifted the industry focus from training to inference, sparking changes in capital spending, chip design, infrastructure, and application models.
As the industry shifts its competitive focus to inference, we can expect a surge in specialized applications that extend beyond chatbots. Inference tasks are inherently distributed, relying on the seamless integration of end devices and edge systems. This will prompt hardware manufacturers to collaborate closely with AI developers to design dedicated inference chips and optimized edge devices for real-time processing, while software teams build tailored drivers and tools to maximize resource use and reduce latency.
Advancements in inference technology will also enable large models to run effectively on a wide range of hardware, including devices with limited power like smartphones, IoT devices, and wearables. This progress tackles current deployment challenges and opens up opportunities in areas like smart homes and mobile health. By shifting the focus to efficient inference, DeepSeek not only lowers costs but also motivates a broader evolution in AI development—reshaping everything from chip design to the end-user experience.
From a broader perspective, we also observe that DeepSeek, being a Chinese model, has raised concerns around data privacy and censorship of sensitive topics. While politicians and large financial institutions might view the Chinese company as a threat, it is generating excitement within the startup world. Being open source democratizes access to cutting-edge innovation, which benefits the broader ecosystem. Its power has already impacted companies like OpenAI, prompting calls for OpenAI to reconsider its closed-source approach, with Sam Altman expressing regret over that decision.

Looking ahead, the dynamics between open and closed-source AI models will likely continue to shift in complex ways, but DeepSeek has undeniably made a positive contribution. Throughout history, technological advancement and human progress have always been intertwined. As we navigate this crucial period in AI development, we hope to foster a legacy of cooperation and mutual benefit. The path forward requires balancing innovation with ethical considerations, ensuring that AI technologies serve humanity's collective interests rather than deepening existing divides. By embracing diverse approaches and perspectives, including those from different cultural and economic systems, we can create an AI landscape that truly benefits all.